17 de mayo de 2024
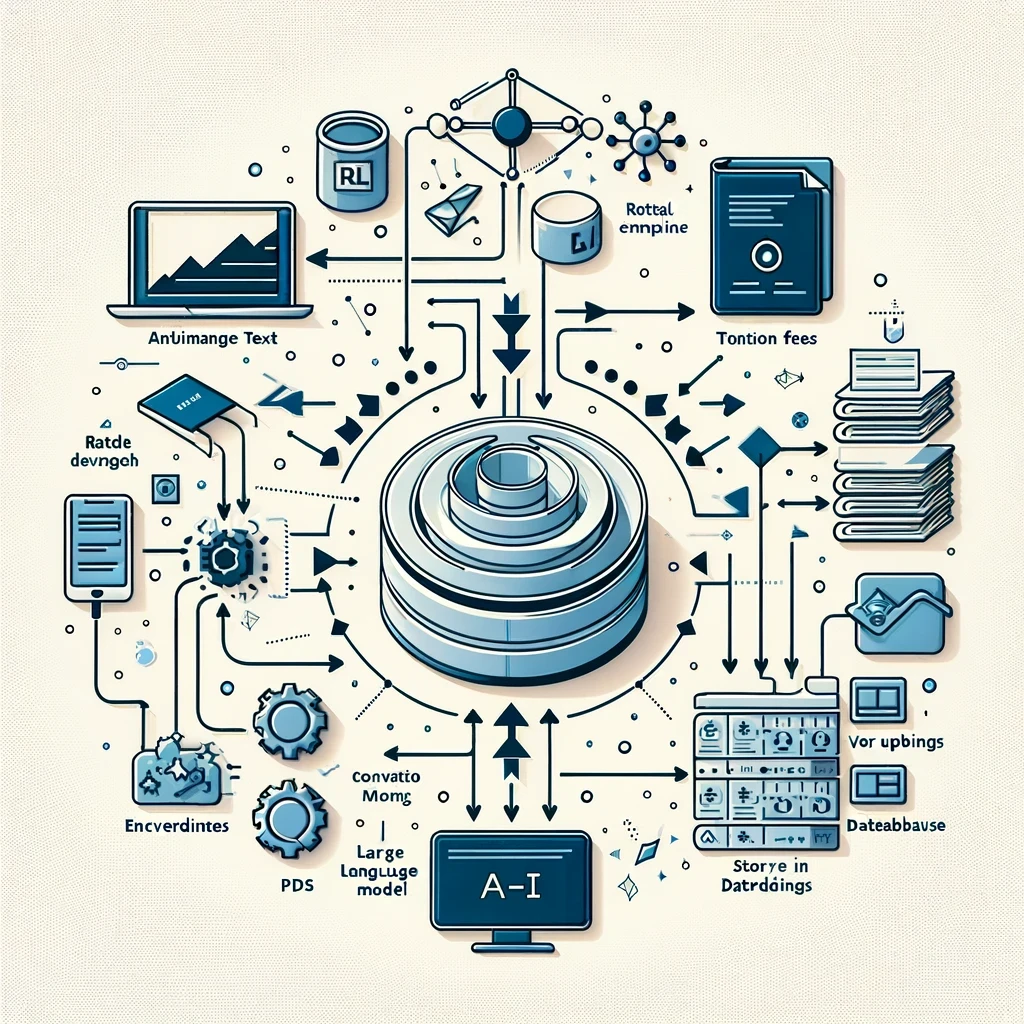
Los RAG (Retrieval Augmented Systems) son sistemas que sirven para procesar, indexar y buscar textos a partir de una base de datos, permitiendo que un LLM (Large Language Model) acceda a información que no es parte de su entrenamiento. De esta manera, podemos ampliar el conocimiento sobre el que el LLM trabaja, ya sea para incorporar información más reciente, de un dominio muy específico o datos privados de una empresa o usuario.
Los sistemas RAG constan de varias partes que están vinculadas con las etapas o procesos que hay que llevar a cabo. A continuación, vamos a describir a grandes rasgos el proceso y a desglosar cada uno de sus componentes.
Fuentes de datos
En primer lugar, debemos definir qué tipo de fuente de datos vamos a usar para el RAG: puede ser desde un archivo de texto hasta un video, pasando por un PDF, un archivo de audio, una tabla o una base de datos SQL. Salvo excepciones, el procesamiento del archivo base debería terminar siempre en un texto plano. Si fuera posible, en cada interacción con el LLM le pasaríamos el 100% del archivo de texto resultante para que sirva como contexto en la interacción con el usuario. Sin embargo, por el momento (marzo de 2024) esto no es eficiente, por lo que debemos recortar el texto en pedazos más pequeños y pasarle al LLM solo lo relevante para resolver la interacción con el usuario.
División en fragmentos (chunks)
El primer paso consiste en dividir el texto en pedazos (chunks). No solo tenemos que definir el tamaño de estos chunks (cuántas palabras incluye), sino que también podemos definir un overlap, es decir, una superposición entre un chunk y el otro para que pese más el contexto en el que cada palabra está inserta. Una vez tenemos los chunks con overlap, tenemos que transformarlos en embeddings, es decir, pasar de palabras a vectores numéricos.
Almacenamiento en base de datos
Una vez tenemos los vectores numéricos que representan las palabras del texto, los almacenamos en una base de datos vectorial. Estas bases están optimizadas para hacer más eficiente la búsqueda. Lo que nos queda es definir el mecanismo con el cual realizaremos la búsqueda. Es decir, cuál es la métrica o algoritmo que vamos a utilizar para encontrar los textos más relevantes para la interacción con el usuario y qué cantidad de resultados queremos devolver.
Búsqueda de fragmentos relevantes
Cada vez que hay una interacción del usuario que requiera consultar en la base de datos, deberíamos ejecutar este mecanismo de búsqueda para traer los resultados más relevantes. Esos fragmentos los pasamos como contexto al LLM y este los utiliza para responder la consulta o resolver la interacción.
Sistemas en producción
Hasta aquí hemos visto el esquema de cómo funciona un sistema RAG, pero esto no termina aquí. Como todo sistema, cuando queremos llevarlo a producción, debemos tener en cuenta algunos elementos adicionales. Por ejemplo, cada cuánto hay que procesar nuevos archivos, si hay que eliminar archivos viejos, establecer mecanismos y métricas de evaluación para entender si es necesario modificar los parámetros del sistema (tamaño de los chunks, overlap, cantidad de fragmentos devueltos en la búsqueda, métrica utilizada) o diferenciarlas por tópicos de conversación. Todo esto sin contar las especificaciones de la puesta en producción del LLM: limitaciones, restricciones, seguridad, privacidad, etcétera.
Si te interesa conocer más en detalle los distintos pasos de los que consta un RAG, puedes continuar en esta nota.